
Docker Desktop for Mac runs the Docker engine and Linux containers in a helper LinuxKit VM since macOS doesn’t have native container support. The helper VM has its own internal clock, separate from the host’s clock. When the two clocks drift apart then suddenly commands which rely on the time, or on file timestamps, may start to behave differently. For example “make” will stop working properly across shared volumes (“docker run -v”) when the modification times on source files (typically written on the host) are older than the modification times on the binaries (typically written in the VM) even after the source files are changed. Time drift can be very frustrating as you can see by reading issues such as https://github.com/docker/for-mac/issues/2076.
Wait, doesn’t the VM have a (virtual) hardware Real Time Clock (RTC)?
When the helper VM boots the clocks are initially synchronised by an explicit invocation of “hwclock -s” which reads the virtual RTC in HyperKit. Unfortunately reading the RTC is a slow operation (both on physical hardware and virtual) so the Linux kernel builds its own internal clock on top of other sources of timing information, known as clocksources. The most reliable is usually the CPU Time Stamp Counter (“tsc”) clocksource which measures time by counting the number of CPU cycles since the last CPU reset. TSC counters are frequently used for benchmarking, where the current TSC value is read (via the rdtsc instruction) at the beginning and then again at the end of a test run. The two values can then be subtracted to yield the time the code took to run in CPU cycles. However there are problems when we try to use these counters long-term as a reliable source of absolute physical time, particularly when running in a VM:
- There is no reliable way to discover the TSC frequency: without this we don’t know what to divide the counter values by to transform the result into seconds.
- Some power management technology will change the TSC frequency dynamically.
- The counter can jump back to 0 when the physical CPU is reset, for example over a host suspend / resume.
- When a virtual CPU is stopped executing on one physical CPU core and later starts executing on another one, the TSC counter can suddenly jump forwards or backwards.
The unreliability of using TSC counters can be seen on this Docker Desktop for Mac install:
$ docker run --rm --privileged alpine /bin/dmesg | grep clocksource … [ 3.486187] clocksource: Switched to clocksource tsc [ 6963.789123] clocksource: timekeeping watchdog on CPU3: Marking clocksource 'tsc' as unstable because the skew is too large: [ 6963.792264] clocksource: 'hpet' wd_now: 388d8fc2 wd_last: 377f3b7c mask: ffffffff [ 6963.794806] clocksource: 'tsc' cs_now: 104a0911ec5a cs_last: 10492ccc2aec mask: ffffffffffffffff [ 6963.797812] clocksource: Switched to clocksource hpet
Many hypervisors fix these problems by providing an explicit “paravirtualised clock” interface, providing enough additional information to the VM to allow it to correctly convert a TSC value to seconds. Unfortunately the Hypervisor.framework on the Mac does not provide enough information (particularly over suspend/resume) to allow the implementation of such a paravirtualised timesource so we reported the issue to Apple and searched for a workaround.
How bad is this in practice?
I wrote a simple tool to measure the time drift between a VM and the host– the source is here. I created a small LinuxKit test VM without any kind of time synchronisation software installed and measured the “natural” clock drift after the VM boots:
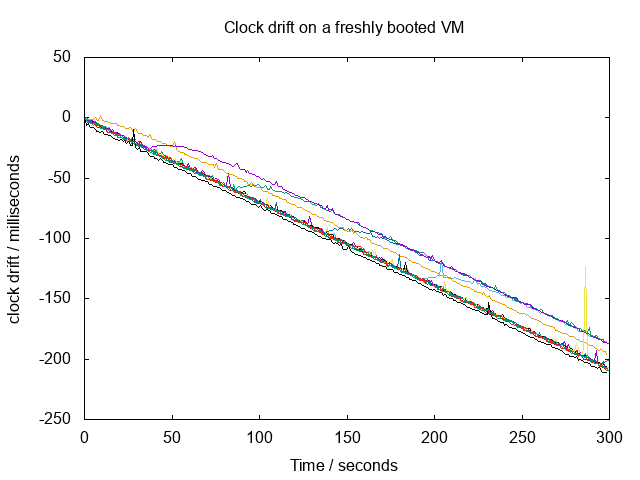
Each line on the graph shows the clock drift for a different test run. From the graph it appears that the time in the VM loses roughly 2ms for every 3s of host time which passes. Once the total drift gets to about 1s (after approximately 1500s or 25 minutes) it will start to get really annoying.
OK, can we turn on NTP and forget about it?
The Network Time Protocol (NTP) is designed to keep clocks in sync so it should be ideal. The question then becomes
- which client?
- which server?
How about using the “default” pool.ntp.org like everyone else?
Many machines and devices uses the free pool.ntp.org as their NTP server. This is a bad idea for us for several reasons:
- it’s against their [guidelines](http://www.pool.ntp.org/en/vendors.html) (although we could register as a vendor)
- there’s no guarantee clocks in the NTP server pool are themselves well-synchronised
- people don’t like their Mac sending unexpected UDP traffic; they fear it’s malware infestation
- anyway… we don’t want the VM to synchronise with atomic clocks in some random physics lab, we want it to synchronise with the host (so the timestamps work). If the host itself has drifted 30 minutes away from “real” time, we want the VM to also be 30 minutes away from “real” time.
Therefore in Docker Desktop we should run our own NTP server on the host, serving the host’s clock.
Which server implementation should we use?
The NTP protocol is designed to be robust and globally scalable. Servers with accurate clock hardware (e.g. an atomic clock or a GPS feed containing a signal from an atomic clock) are relatively rare so not all other hosts can connect directly to them. NTP servers are arranged in a hierarchy where lower “strata” synchronise with the stratum directly above and end-users and devices synchronise with the servers at the bottom. Since our use-case only involves one server and one client this is all completely unnecessary and so we use “Simplified NTP” as described in RFC2030 which enables clients (in our case the VM) to synchronise immediately with a server (in our case the host).
Which NTP client should we use (and does it even matter)?
Early versions of Docker Desktop included openntpd from the upstream LinuxKit package. The following graph shows the time drift on one VM boot where openntpd runs for the first 10000s and then we switch to the busybox NTP client:

The diagram shows the clock still drifting significantly with openntpd running but it’s “fixed” by running busybox — why is this? To understand this it’s important to first understand how an NTP client adjusts the Linux kernel clock:
- adjtime (3) – this accepts a delta (e.g. -10s) and tells the kernel to gradually adjust the system clock avoiding suddenly moving the clock forward (or backward, which can cause problems with timing loops which aren’t using monotonic clocks)
- adjtimex (2) – this allows the kernel clock *rate* itself to be adjusted, to cope with systematic drift like we are suffering from
- settimeofday (2) – this immediately bumps the clock to the given time
If we look at line 433 of openntpd ntp.c (sorry no direct link in cvsweb) then we can see that openntpd is using adjtime to periodically add a delta to the clock, to try to correct the drift. This could also be seen in the openntpd logs. So why wasn’t this effective?
The following graph shows how the natural clock drift is affected by a call to adjtime(+10s) and adjtime(-10s):

It seems the “natural” drift we’re experiencing is so large it can’t be compensated for solely by using “adjtime”. The reason busybox performs better for us is because it adjusts the clock rate itself using “adjtimex”.
The following graph shows the change in kernel clock frequency (timex.freq) viewed using adjtimex. For the first 10000s we use openntpd (and hence the adjustment is 0 since it doesn’t use the API) and for the rest of the graph we used busybox:

Note how the adjustment value remains flat and very negative after an initial spike upwards. I have to admit when I first saw this graph I was disappointed — I was hoping to see something zig-zag up and down, as the clock rate was constantly micro-managed to remain stable.
Is there anything special about the final value of the kernel frequency offset?
Unfortunately it is special. From the adjtimex (2) manpage:
ADJ_FREQUENCY
Set frequency offset from buf.freq. Since Linux 2.6.26, the
supplied value is clamped to the range (-32768000, +32768000).
So it looks like busybox slowed the clock by the maximum amount (-32768000) to correct the systematic drift. According to the adjtimex(8) manpage a value of 65536 corresponds to 1ppm, so 32768000 corresponds to 500ppm. Recall that the original estimate of the systematic drift was 2ms every 3s, which is about 666ppm. This isn’t good: this means that we’re right at the limit of what adjtimex can do to compensate for it and are probably also relying on adjtime to provide additional adjustments. Unfortunately all our tests have been on one single machine and it’s easy to imagine a different system (perhaps with different powersaving behaviour) where even adjtimex + adjtime would be unable to cope with the drift.
So what should we do?
The main reason why NTP clients use APIs like adjtime and adjtimex is because they want
- monotonicity: i.e. to ensure time never goes backwards because this can cause bugs in programs which aren’t using monotonic clocks for timing, for example How and why the leap second affected Cloudflare DNS; and
- smoothness: i.e. no sudden jumping forwards, triggering lots of timing loops, cron jobs etc at once.
Docker Desktop is used by developers to build and test their code on their laptops and desktops. Developers routinely edit files on their host with an IDE and then build them in a container using docker run -v. This requires the clock in the VM to be synchronised with the clock in the host, otherwise tools like make will fail to rebuild changed source files correctly.
Option 1: adjust the kernel “tick”
According to adjtimex(8) it’s possible to adjust the kernel “tick”:
Set the number of microseconds that should be added to the system time for each kernel tick interrupt. For a kernel with USER_HZ=100, there are supposed to be 100 ticks per second, so val should be close to 10000. Increasing val by 1 speeds up the system clock by about 100 ppm,
If we knew (or could measure) the systematic drift we could make a coarse-grained adjustment with the “tick” and then let busybox NTP to manage the remaining drift.
Option 2: regularly bump the clock forward with settimeofday (2)
If we assume that the clock in the VM is always running slower than the real physical clock (because it is virtualised, vCPUs are periodically descheduled etc) and if we don’t care about smoothness, we could use an NTP client which calls settimeofday (2) periodically to immediately resync the clock.
The choice
Although option 1 could potentially provide the best results, we decided to keep it simple and go with option 2: regularly bump the clock forward with settimeofday (2) rather than attempt to measure and adjust the kernel tick. We assume that the VM clock always runs slower than the host clock but we don’t have to measure exactly how much it runs slower, or assume that the slowness remains constant over time, or across different hardware setups. The solution is very simple and easy to understand. The VM clock should stay in close sync with the host and it should still be monotonic but it will not be very smooth.
We use an NTP client called SNTPC written by Natanael Copa, founder of Alpine Linux (quite a coincidence considering we use Alpine extensively in Docker Desktop). SNTPC can be configured to call settimeofday every n seconds with the following results:

As you can see in the graph, every 30s the VM clock has fallen behind by 20ms and is then bumped forward. Note that since the VM clock is always running slower than the host, the VM clock always jumps forwards but never backwards, maintaining monotonicity.
Just a sec, couldn’t we just run hwclock -s every 30s?
Rather than running a simple NTP client and server communicating over UDP every 30s we could instead run hwclock -s to synchronise with the hardware RTC every 30s. Reading the RTC is inefficient because the memory reads trap to the hypervisor and block the vCPU, unlike UDP traffic which is efficiently queued in shared memory; however the code would be simple and an expensive operation once every 30s isn’t too bad. How well would it actually keep the clock in sync?

Unfortunately running hwclock -s in a HyperKit Linux VM only manages to keep the clock in sync within about 1s, which would be quite noticeable when editing code and immediately recompiling it. So we’ll stick with NTP.
Final design
The final design looks like this:

In the VM the sntpc process sends UDP on port 123 (the NTP port) to the virtual NTP server running on the gateway, managed by the vpnkit process on the host. The NTP traffic is forwarded to a custom SNTP server running on localhost which executes gettimeofday and replies. The sntpc process receives the reply, calculates the local time by subtracting an estimate of the round-trip-time and calls settimeofday to bump the clock to the correct value.
In Summary
- Timekeeping in computers is hard (especially so in virtual computers)
- There’s a serious source of systematic drift in the macOS Hypervisor.framework, HyperKit, Linux system.
- Minimising time drift is important for developer use-cases where file timestamps are used in build tools like make
- For developer use-cases we don’t mind if the clock moves abruptly forwards
- We’ve settled on a simple design using a standard protocol (SNTP) and a pre-existing client (sntpc)
- The new design is very simple and should be robust: even if the clock drift rate is faster in future (e.g. because of a bug in the Hypervisor.framework or HyperKit) the clock will still be kept in sync.
- The new code has shipped on both the stable and the edge channels (as of 18.05)
Feedback
0 thoughts on "Addressing Time Drift in Docker Desktop for Mac"